静态分析复习
1. 静态分析概述
静态分析(Static Analysis)和动态测试(Dynamic Testing)的区别是什么?
静态分析(Static Analysis) 是指在实际运行程序 P 之前,通过分析静态程序P 本身来推测程序的行为,并判断程序是否满足某些特定的 性质(Property) Q 。
完全性(Soundness)、正确性(Completeness)、假积极(False Positives)和假消极(False Negatives)分别是什么含义?
完全性:真相一定包含在给出的答案S中,过近似,false positive(被判定为true,但实际是false)
正确性:S给出的答案一定包含在真相中,欠近似,false negative(被判定是false(没找出来),但实际是true)
为什么静态分析通常需要尽可能保证完全性?
以debug为例,有十个错,编译器爆12个warning,总比只爆出8个好
如何理解抽象(Abstraction)和过近似(Over-Approximation)?
抽象:程序P有具体值集DC,S要基于研究的性质Q设计一个抽象值集DA,fDC→DA。

状态函数:单独一个从具体到抽象的转变函数
转移函数:全局转移到抽象的函数
向上是undef,向下T的unknown
3. 数据流分析-应用
数据流分析(Data Flow Analysis, DFA) 是指分析数据在程序中是怎样流动的
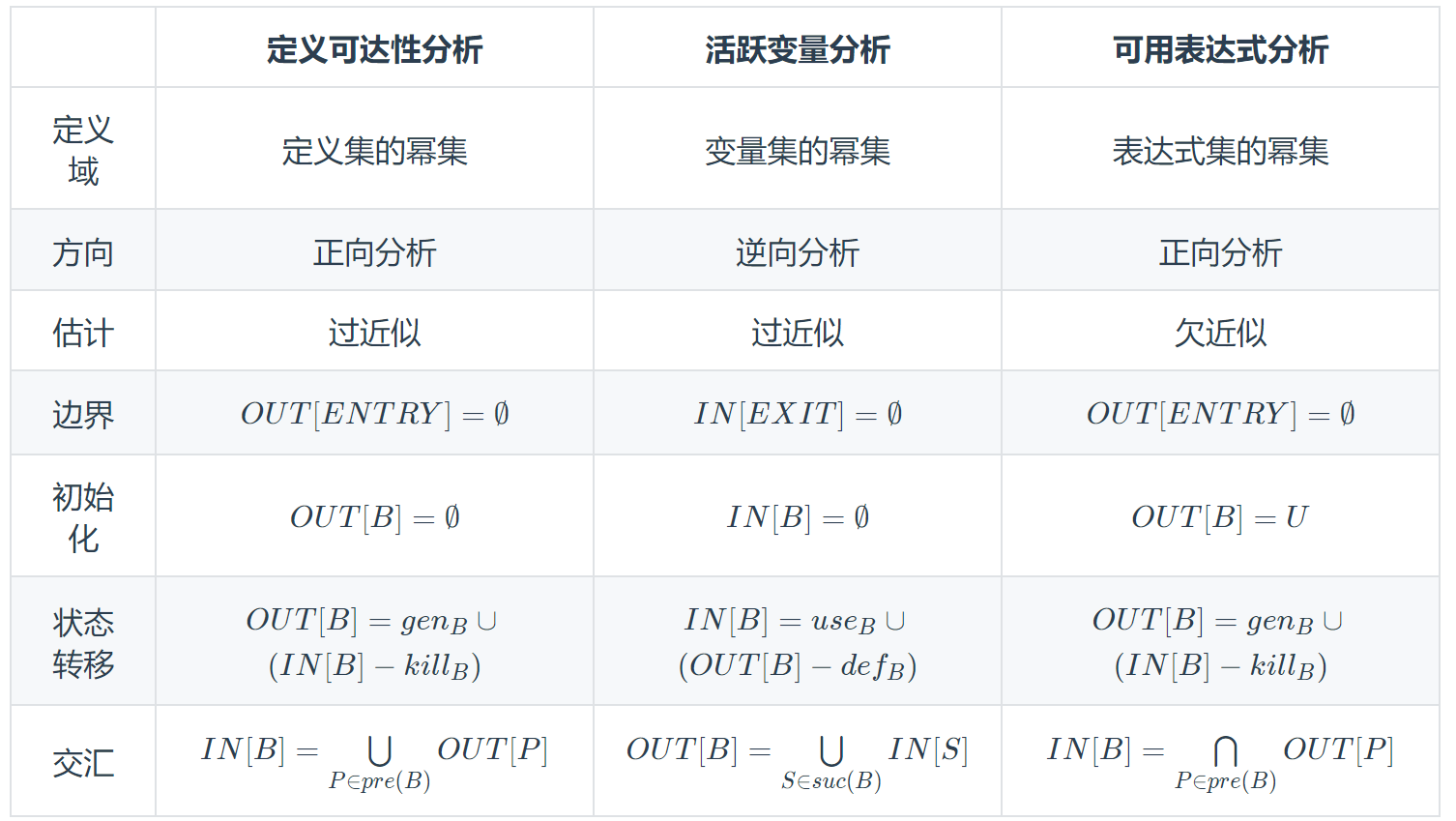
定义可达性(Reaching Definitions)分析、活跃变量(Live Variables)分析和可用表达式(Avaliable Expressions)分析分别是什么含义?
先kill再加新的
A 定义可达性:分析每个程序点处能够到达的定义的过程,描述了一个定义可能的 最长的 生存期在 DFG 的入口处为每个变量 v 赋予一个伪定义,若v在p点被用,而仍是dummy值,则可能存在变量未定义错误。(比如语句D2 y = q +2这句定义出的y值能不能到达D5)
活跃变量
算法3.2 活跃变量分析算法
OUT[B] = In[S]的并集:上一个node的out和它下面node的in
IN[B] = useB(OUT[B] - defB):同一个block的in和一个block的out
可用表达式:subExpression,所有路径可用才算可用
上述三种数据流分析(Data Flow Analysis)有哪些不同点?又有什么相似的地方?
如何理解数据流分析的迭代算法?数据流分析的迭代算法为什么最后能够终止?
数据流分析迭代算法:
D:direction
L:lattice 交汇或联合操作transfer edge
F:V到V的转移函数transferNode
假设集合操作是常数项时间,则数据流分析的迭代算法的时间复杂度为O(kh) ,其中 k 为 CFG 的结点个数, ℎ 为定义域格的高度
单调性到达不动点
4. 数据流分析-基础
偏序集的最小上界 vS(有下面所有的元素并集),最大上界是 ∧S(是它上面所有元素的交集)。并不是每一个偏序集都有最小上界或者最大下界
如何从函数的角度来看待数据流分析的迭代算法?
F(x) = x
格和全格的定义是什么?
考虑偏序集 (P,⪯) ,如果 ∀a,b∈P , a∨b 和 a∧b* 都存在,则我们称 (P,⪯) 为 格(Lattice)
简单理解,格是每对元素都存在最小上界和最大下界的偏序集
考虑偏序集 (P,⪯) ,如果 ∀S⊆P , ∨S 和 ∧S 都存在,则我们称 (P,⪯) 为 全格(Complete Lattice)
全格:⊤=∨P 称作 顶部(Top),⊥=∧P 称作 底部
每一个有限格(Finite Lattice)(P,⪯) ( P 是有限集)都是一个全格。
如何理解不动点定理?
fL -> L(L是格)是单调的
L是有限集
A 再手动推导一次
对于3. 的应用,交集(交汇)与联合是单调,格是有限的

怎样使用格来总结可能性分析与必然性分析?
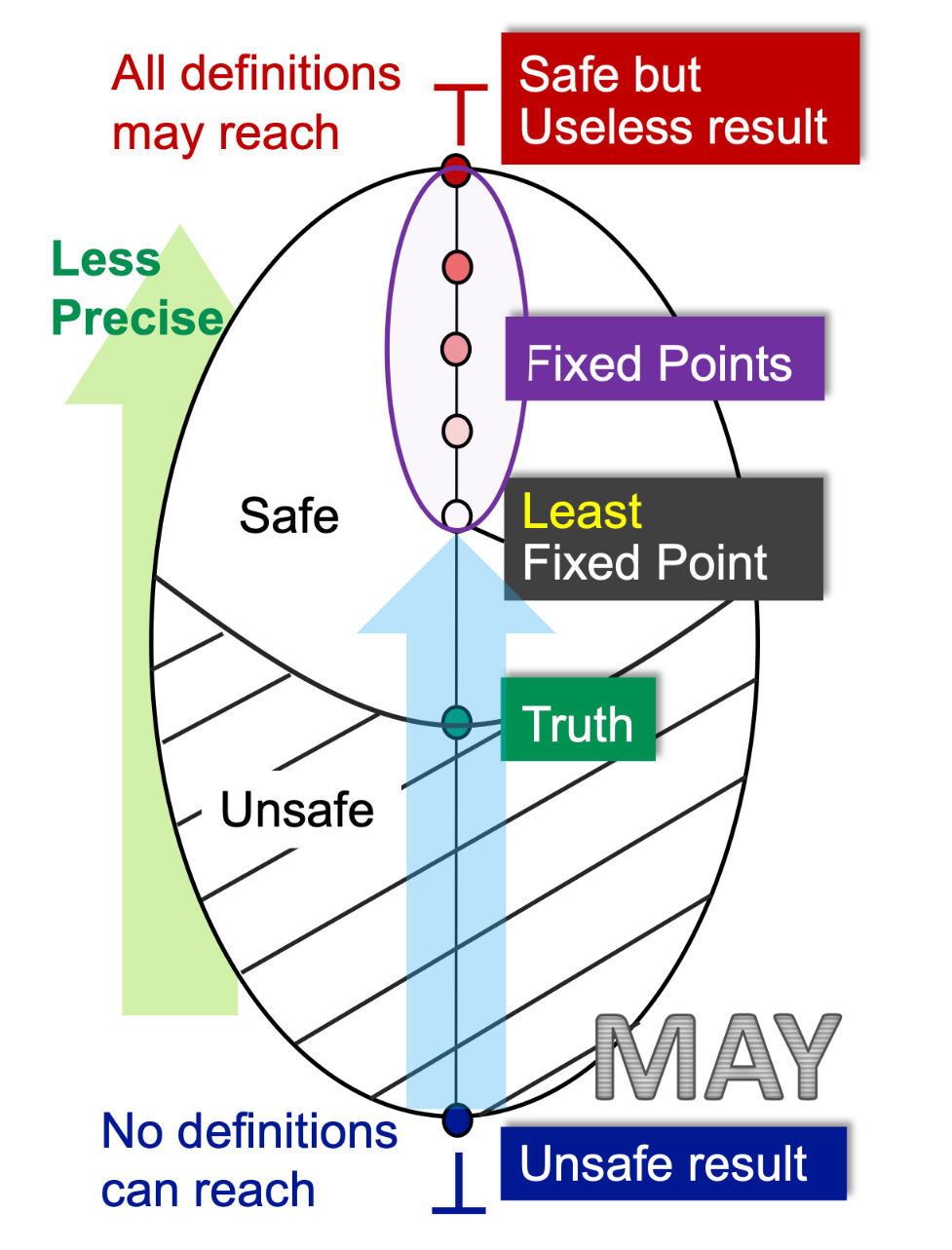
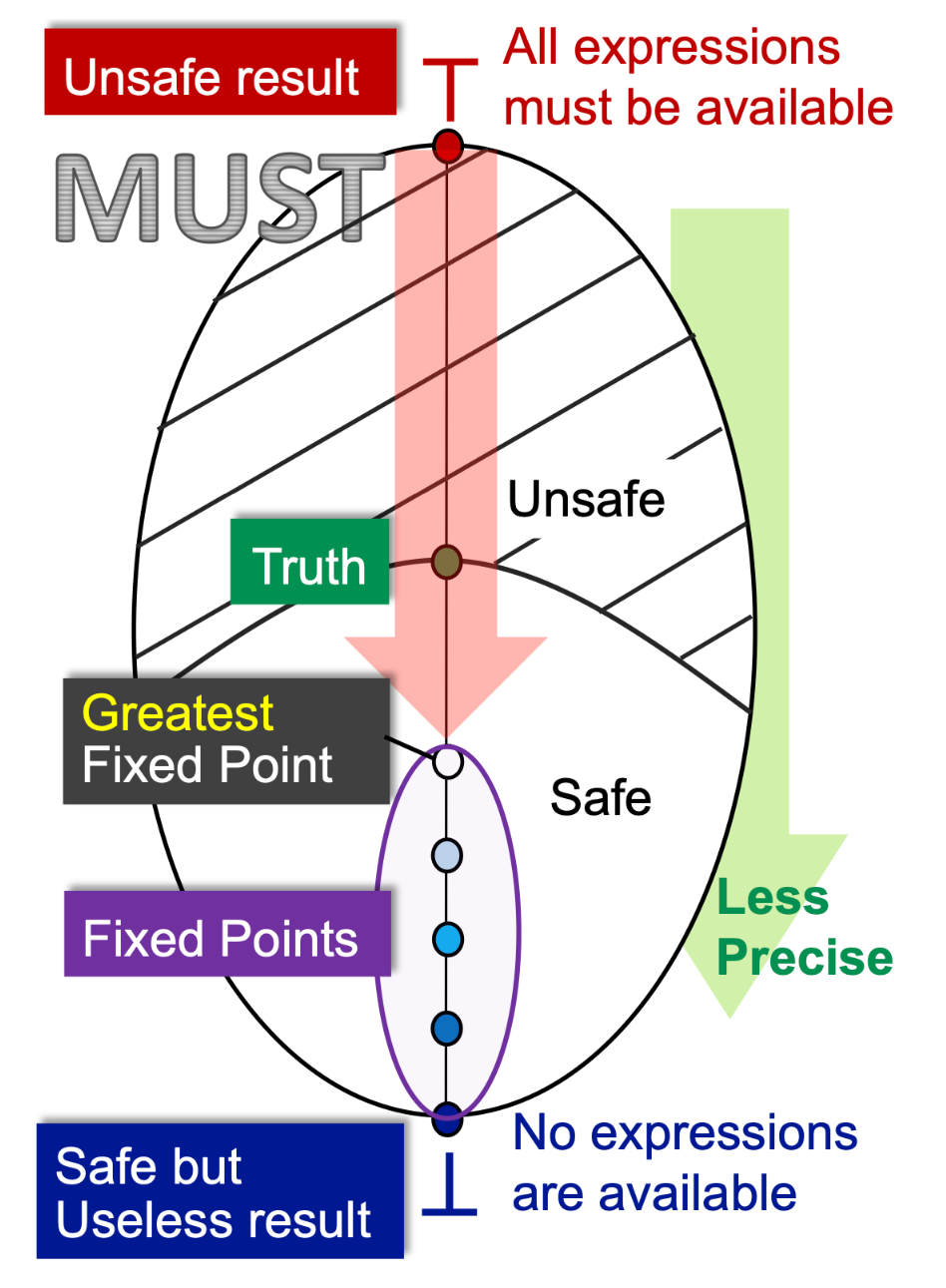
迭代算法提供的解决方案与MOP相比而言精确度如何?
MOP:全路交汇
分配律:A 再证一次

什么是常量传播(Constant Propagation)分析?
数据流分析的工作表算法(Worklist Algorithm)是什么?
工作表算法是对迭代算法的优化,用一个集合储存下一次遍历会发生变化的基块,这样,已经达到不动点的基块就可以不用重复遍历了。
5. 过程间分析
构建调用图:
类层级结构
指针分析
......
如何通过类层级结构分析(Class Hierarchy Analysis, CHA)来构建调用图(Call Graph)?
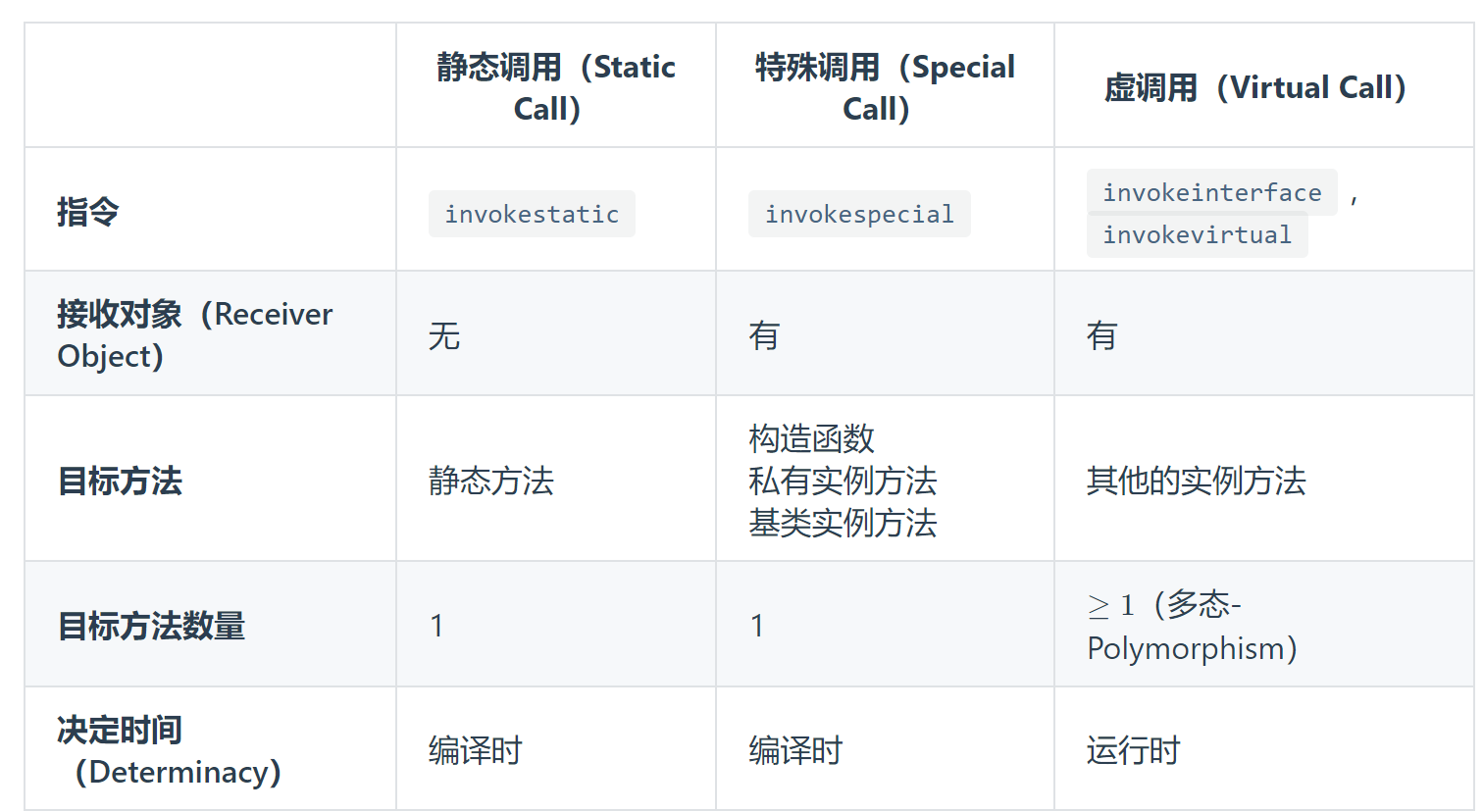
对于某个形如
o.foo()的调用点,记接收对象的类型为 c ,方法签名为 m ,定义在运行时刻解析调用点所调用的目标方法的过程为方法派发(Method Dispatch),记为Dispatch(c,m*)
简单来说,就是先从接收对象类型的方法找,如果找不到,就找父类的方法
算法 5.1 虚调用的方法派发算法
CHA假设声明类型为
A的接收变量a可能会指向A类以及A的所有 子类(Subclass) 的对象当我们说 c 的子类的时候,包括 c 的直接子类和间接子类。
算法5.2 CHA的调用解析(Call Resolution)算法
算法5.3 调用图构建(Call Graph Construction)算法
如何理解过程间控制流图(Interprocedural Control-Flow Graph, ICFG)的概念?
之前的CFG边 + 调用边 + 返回边
如何理解过程间数据流分析(Interprocedural Data-Flow Analysis, IDFA)的概念?
基于ICFG的数据流分析
数据流在ICFG的边转移:transfer edge
普通边转移
调用-返回边转移
调用边转移
返回边转移
CFG结点transfer node
调用结点转移
其他结点转移
如何进行过程间常量传播(Interprocedural Constant Propagation)分析?
6. 指针分析
什么是指针分析(Pointer Analysis)?
我们将分析一个指针可能指向的 内存区域(Memory Location) ,以 程序(Program) 为输入,以程序中的 指向关系(Point-to Relation) 为输出的分析称作 指针分析(Pointer Analysis) 。
如何理解指针分析的关键因素(Key Factors)?
堆抽象:对堆区内存建模:分配点
A 分配点抽象:将同一 分配点(Allocation Site ,通常是一条
new语句 ) 处分配内存而产生的所有具体对象抽象成一个抽象的对象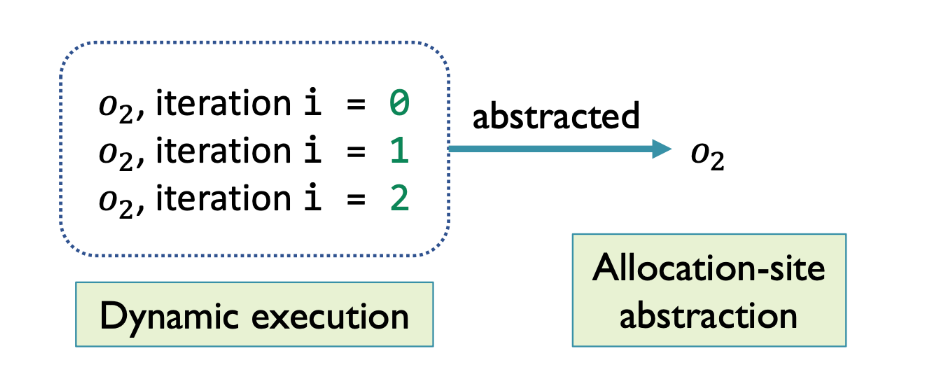
上下文敏感性:对调用语境建模,是否区分调用语境
流敏感性:是否尊重语句执行顺序
分析范围:全程序、需求驱动
我们在指针分析的过程中具体都分析些什么?
本地变量
静态域:视为global variable
实例域:建模成x指向对象的域f
数组元素:建模成array指向的一个对象,这个对象只有arr一个字段field
理解:本来数组a也是base,然后随下标不同能指向很多,与实例域相模仿是最合适的
重要原因:
array.arr指向的是"x"(arr[0])和"y"(arr[1])两个可能值,并不会存在后来居上覆盖前者的问题。
7. 指针分析-基础
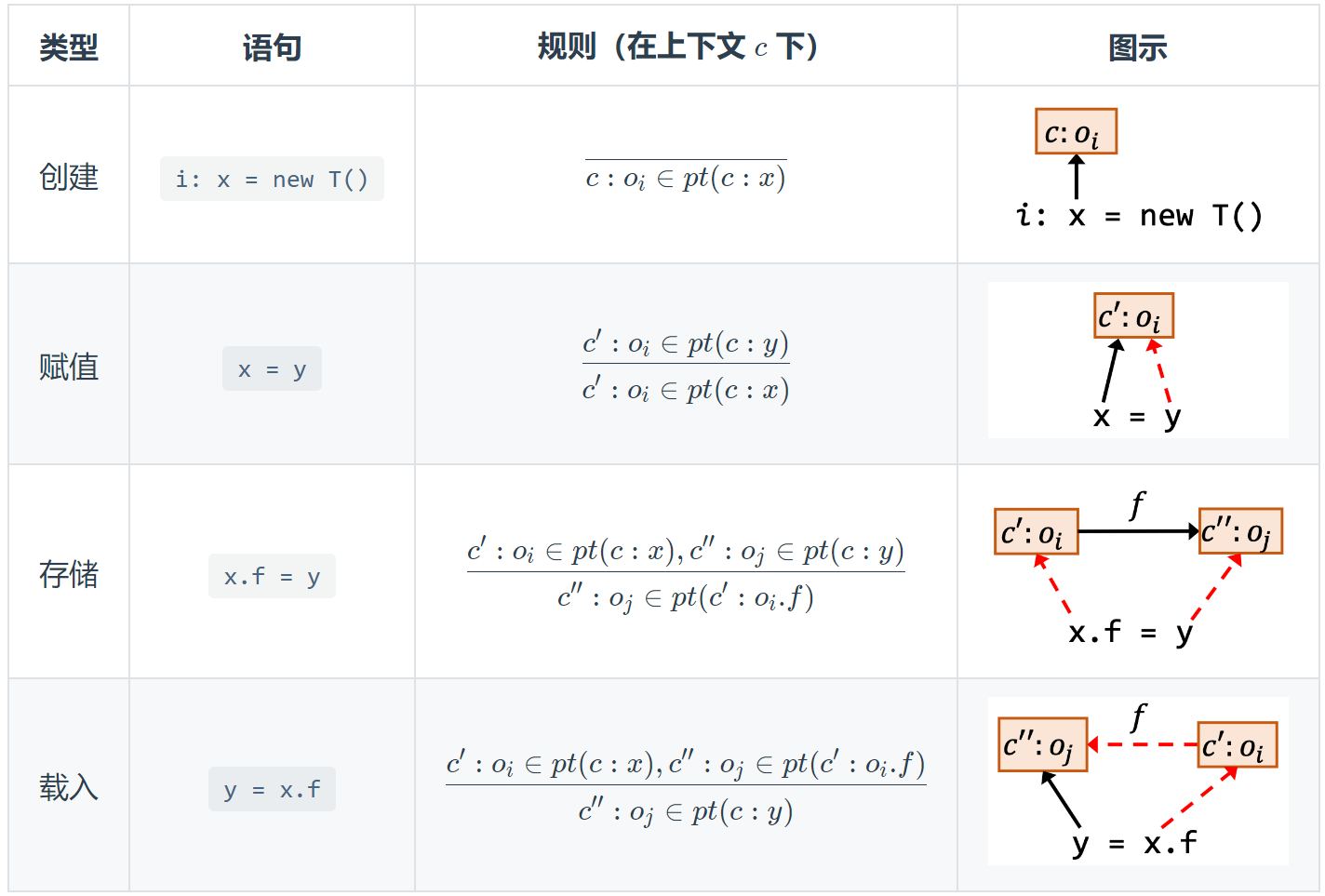
指针分析的规则(Pointer Analysis Rules)是什么?


如何理解指针流图(Pointer Flow Graph)?
指的是表示对象如何在程序中的指针之间流动的有向图
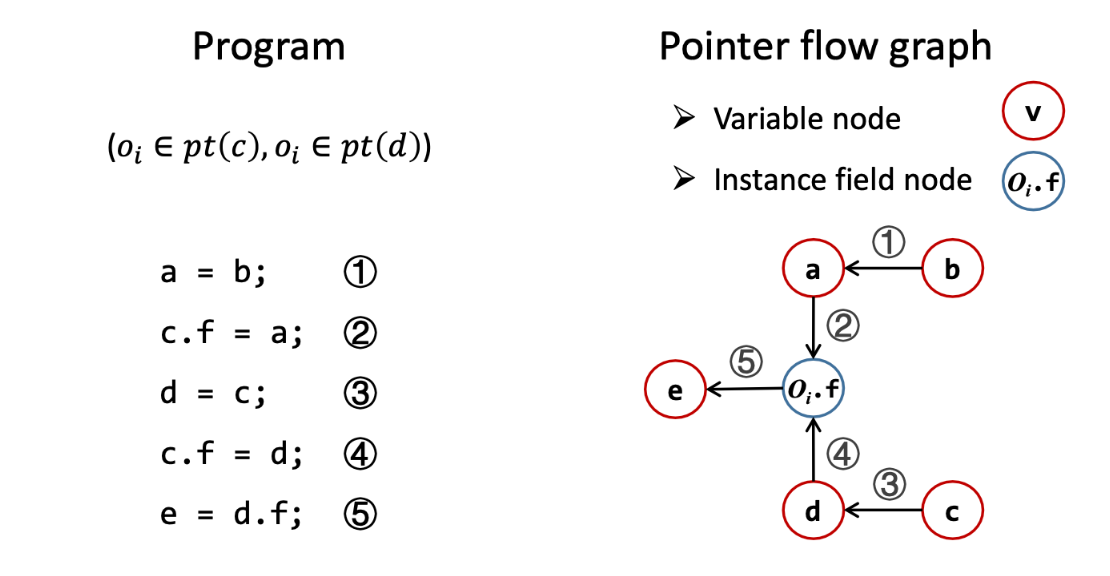
指针分析算法(Pointer Analysis Algorithms)的基本过程是什么?
略
如何理解方法调用(Method Call)中指针分析的规则?
怎样理解过程间的指针分析算法(Inter-procedural Pointer Analysis Algorithm)?
即时调用图构建(On-the-fly Call Graph Construction)的含义是什么?
指针分析和调用图构建之间就像指针分析和指针流图构建之间一样,是相互依赖的,只有可达的方法和语句才会被分析
8. 指针分析-上下文敏感
上下文敏感(Context Sensitivity, C.S.)是什么?
区分调用语境
上下文敏感堆(C.S. Heap)是什么?
之前:将同一分配点处产的所有对象抽象成一个对象
上下文敏感:分配点处分配的对内存也应该是上下文敏感的
为什么 C.S. 和 C.S. Heap 能够提高分析精度?
不带堆上下文分析这样的代码可能会由于合并不同上下文中的数据流到一个抽象对象中而丢失精度
上下文敏感的指针分析有哪些规则?

Select(c,l,c′:o*i) 根据在调用点 l 处可获得的信息为目标方法 m 选择一个上下文,即目标上下文的生成函数。
Select的输入是调用点 l 、调用点处的上下文 c 、接收对象 c′:o**i;Select的输出是目标方法的的上下文 ct 。
如何理解上下文敏感的指针分析算法(Algorithm for Context-sensitive Pointer Analysis)?
算法8.1 过程间上下文敏感的全程序指针分析算法
常见的上下文敏感性变体(Context Sensitivity Variants)有哪些?
调用点敏感(最后一个调用它的的行数是最后一个)、对象敏感、类型敏感
常见的几种上下文变体之间的差别和联系是什么?
9. 静态分析与安全
信息流安全(Information Flow Security)的概念是什么?
指通过追踪信息是如何在程序中流动的方式,来确保程序安全地处理了它所获得的信息。
如何理解机密性(Confidentiality)与完整性(Integrity)?
机密性:不能让机密信息泄露
完整性:阻止不信任的信息污染到受信任的信息
什么是显式流(Explicit)和隐蔽信道(Covert Channels)?
显式流:信息可以通过直接拷贝的方式进行流动
隐式流:信息可以通过影响控制流的方式向外传递
如何使用污点分析(Taint Analysis)来检测不想要的信息流?


10. 基于datalog的程序分析
datalog是申述式语言
如果一个规则中的每个变量都在至少一个非否定的关系型原子中出现过,那么这个规则就是安全(Safe)的。
在 Datalog 中,一个原子的递归和否定必须分开,否则这个规则可能会包含矛盾,且逻辑推理无法收敛。
Datalog 语言的基本语法和语义是什么?


如何用 Datalog 来实现指针分析?
如何用 Datalog 来实现污点分析?
11. CFL可达与IFDS
什么是CFL可达(CFL-Reachability)?
称返回边和调用边(见定义5.8)相匹配的路径为 可实现路径(Realizable Path),不匹配则称为 不可实现路径(Unrealizable Path)
如果存在从A到B的路径,该路径上每条边的标签组成了某个特定的上下文无关语言的合法字符串。

IFDS(Interprocedural Finite Distributive Subset Problem)的基本想法是什么?
IFDS 是一种通过图可达性的方式进行静态程序分析的框架。
IFDS(Interprocedural Finite Distributive Subset Problem) 指的是一类过程间(Interprocedural)数据流分析的子问题,其流函数具有分配性(Distributive),定义域(Domain,见定义3.5)是有限(Finite)集。

问题:定义 可能未初始化变量(Possibly-uninitialized Variables) 问题:对于 N∗(见定义11.11) 中的每个结点 n ,求在执行 n 之前有可能未初始化的变量集合。
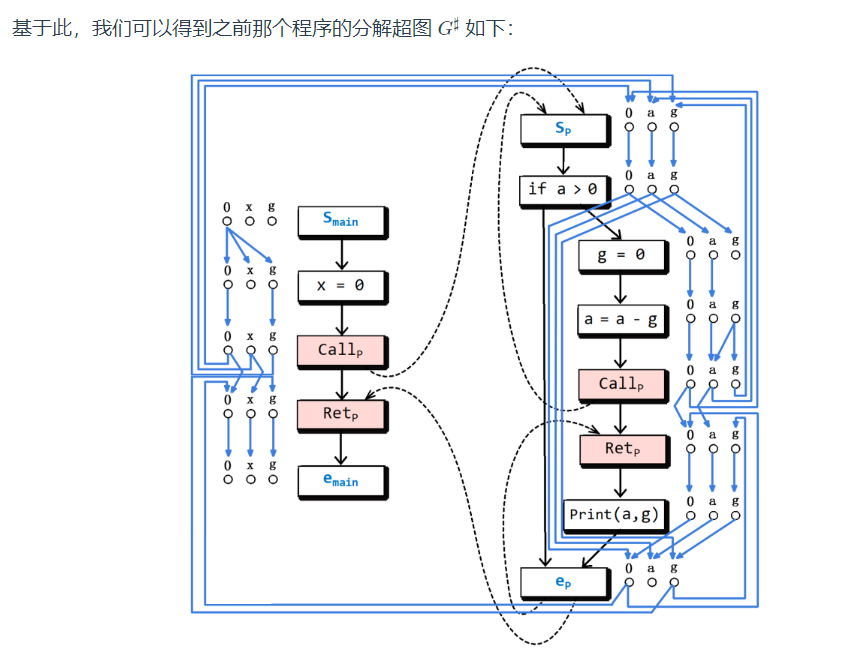
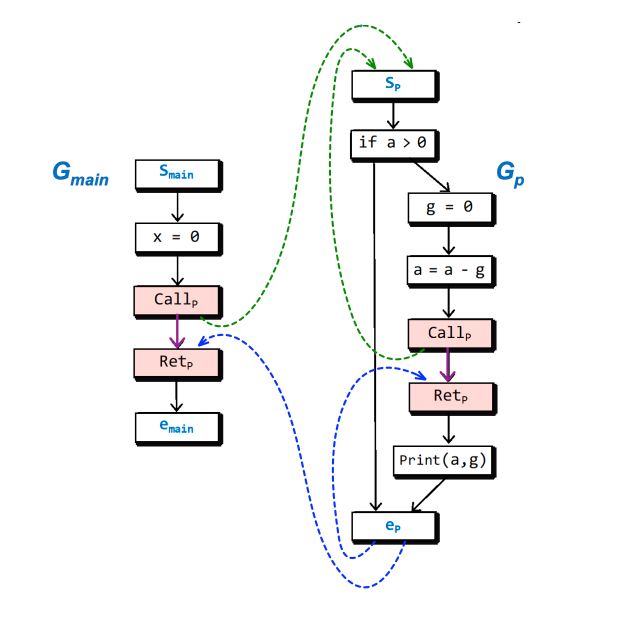
程序——> 超图
G ∗ 是由一组控制流图(Control Flow Graph,见定义2.4与算法2.2) G1,G*2,... 组成的,每个过程 Procedure i 都有一个对应的控制流图 Gi。
流函数——> 代表关系——> 分解超图:
lamdba表达式匿名函数:
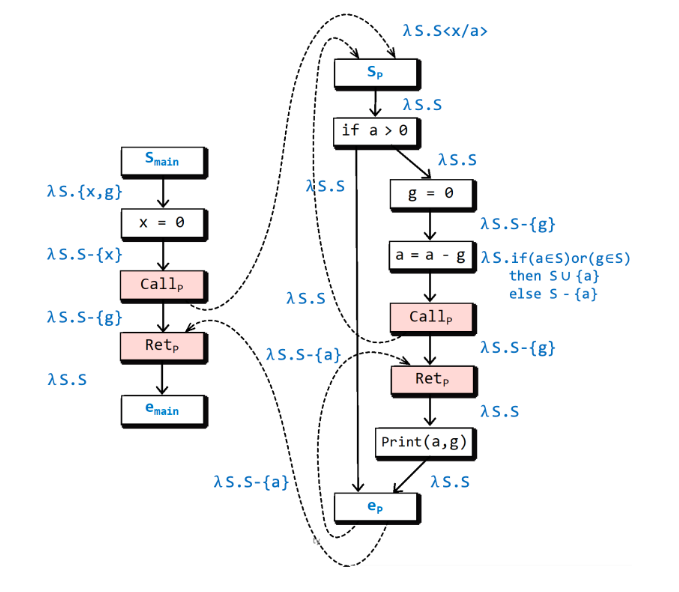
代表关系:
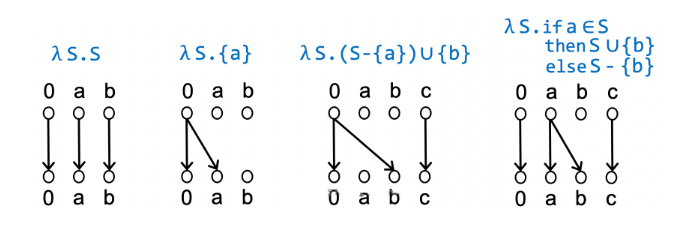
制表算法:CFL可达的路径就是答案
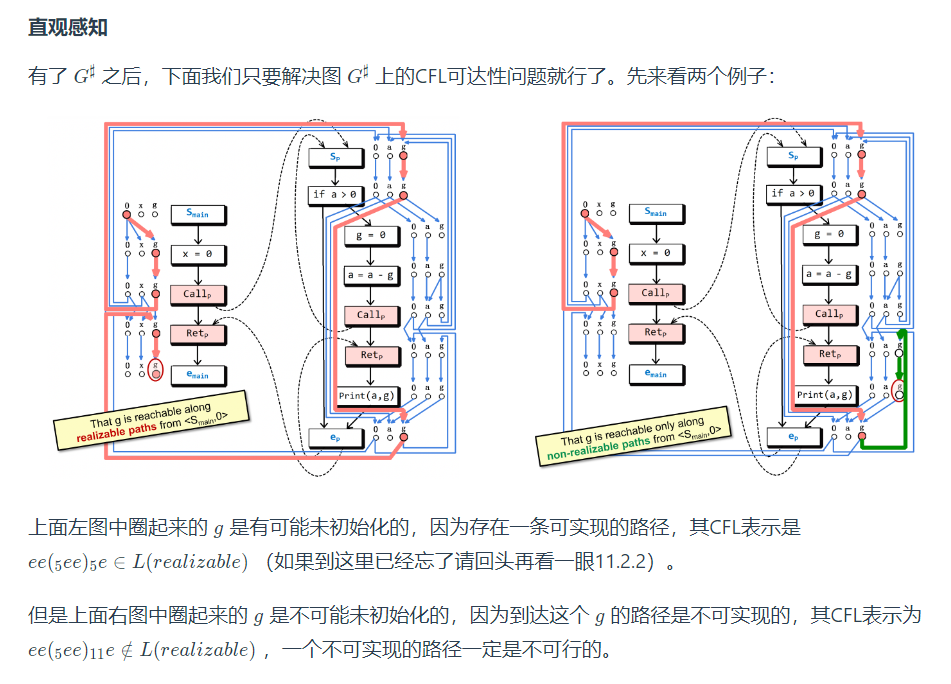
制表算法能够帮助我们把从 (Smain,0) 开始的所有的可实现路径找出来。
怎样的问题可以用IFDS来解决?
过程间、有限、分配性
用IFDS做和上下文敏感区别好处是什么
高效、不用维护繁琐的上下文信息吗?
12. 完全性与近似完全性
近似完全性(Soundiness)的动机和概念是什么?

为什么Java反射(Reflection)和原生代码是难分析的?
java反射:
代码避不开反射,而反射还会产生别的新的过程间的控制流边(调用边、返回边),而这些边会大大影响全程序分析的结果。
反射会修改程序的内部属性,副作用不能忽视
原生代码:
Java原生接口(Java Native Interface, JNI) 是JVM的一个功能模块,允许Java代码和原生代码(C/C++)之间的交互。
静态分析器怎么分析原生java方法,里面甚至都不是java代码
must analysis与may analysis
may analysis
定义可达性(流敏感)
活跃变量(流敏感)
指针分析
must analysis
可用表达式(流敏感)
常量传播吧(流敏感)
不满足分配性
常量传播
指针分析
https://dl.acm.org/doi/10.1145/3571228
https://xiongyingfei.github.io/SA/2022/main.htm
https://xiongyingfei.github.io/SF/2023/
https://stonebuddha.github.io/publication/tangwx17/
编译器项目复习
在创建SSA形式的LLVM IR时,SSA value之间的def-use信息是如何建立的?
ValueHandle TODO
User对Use的管理:
hung off :第一种是独立分配, 在构造User对象时额外分配一个指针用来保存Use数组
not hung off:另一种是co-allocated, 在构造User对象时传入边的数量并分配连续内存同时保存User与Use, 这种情况下HasHungOffUses为false.

ins_new对User的内存分配:
传入op_num
分配内存 sizeof(Use) * use_num + sizeof(Instruction)
Instruction* ins = (Instruction*)(storage+use_size); ins指向storage基地址 + use的偏移地址
user_construct:(此时内存已经分配好)
Use Start = (Use )(place);
Use *End = Start + use_num;
User Obj = (User )(End);
将Start和Obj这两个Use的parent指针指向User,从此就可以user->use_list[0],[1]了
之后Use* user_get_operand_use(),传需要第几个操作数的use就行
ins_new_unary_operator()
调用ins_new之后,调用user_get_operand_use拿到对应操作数的use,之后use_set_value即可
use_set_value中 调用value_add_use(),
void value_add_use(Value *this, Use *U){ use_add_to_list(U, &(this->use_list)); }将这个use加入到value的use_list中
删除的时候:
use_list是双向链表,把自己从list中删去就好
//释放use for(unsigned int i = 0; i < count; i++){ Use *pUse = user_get_operand_use(&this->inst->user,i); if(pUse->Val != NULL) use_remove_from_list(pUse); }
mem2reg
LLVM的mem2reg pass本质上就是识别“局部变量”的模式,并对它们构建SSA形式。
理解:alloca是模拟其分配在栈上的行为,IR是默认先无限寄存器的
是在重命名之后才删除load, store,alloca(只删掉了localVar(local var_int, local var_float),没删address数组的),我们之前做重命名那些的时候,没有提前判断哪些alloca可以Promote,但是每次都先isLocalVar()了
SSA的好处:
dense分析:要用个容器携带所有变量的信息去遍历所有指令,即便某条指令不关心的变量信息也要携带过去
sparse分析:变量的信息直接在def与use之间传播,中间不需要遍历其它不相关的指令。
源程序中对同一个变量的不相关的若干次使用,在SSA形式中会转变成对不同变量的使用,因此能消除很多不必要的依赖关系
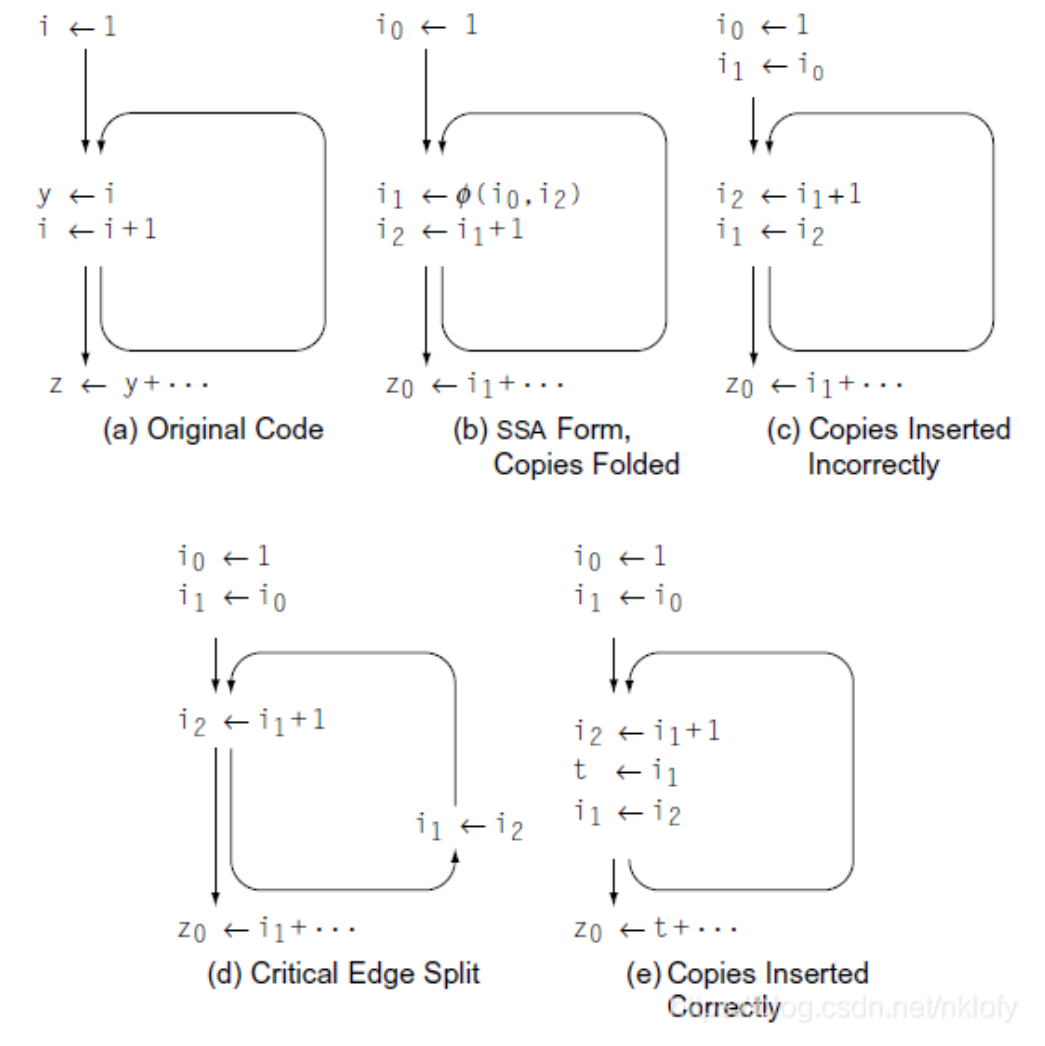
引入critical edge原因:
On a critical edge, the copy insertion described
above breaks down. The copy cannot be inserted into the edge’s source (the predecessor), because it would execute along paths not leading to the f -function.
主要应该还是在循环里才有这种吧
函数内联思路:
每个caller - callee计算一个call(指令+ ,参数 - ,设置一个阈值),如果函数A调用B(A→B),B调用C(B→C),这时如果把C内联到B中,使得本来可以内联到A中的B不再能内联,则模型不内联C到B中,从而保证B内联到A中
get_param_list填满参数,记下参数个数,%号比个数小的都是参数
copy inst :是参数的就直接用get_param_list得到的参数,别的就用alias_map的对应值
alloca记得提前,要该数组alias的关系
若左值有名字,就hashMapPut对应关系到aliasMap中
读到Label和phi语句,用blockMap和phiMap存起来,最后全完了再一起处理
处理最后的一句ret和call 将ret的值替换call的左值,valueReplaceAll(记得改phi!! ) ret void的情况不用管
函数内联优点:减少调用函数的开销、增加编译器优化机会
循环展开优点:减少分支开销: 循环展开可以减少循环迭代次数,从而降低分支指令的开销。分支预测错误以及相关的流水线刷新操作都是造成性能损失的主要因素,循环展开可以有效减少这些开销;增加指令级并行性: 循环展开后,可以将原来在循环中依次执行的指令并行执行,从而提高指令级并行性。这可以更好地利用现代CPU的多发射机制和乱序执行技术,充分发挥硬件资源的潜能。
循环展开思路:
dfs遍历循环,一个loop一个loop处理
将head块中的phi信息存入v_new_valueMap和exit_phi_map:
(variable ,对应phi的pairSet )
开始多次复制,如果是第一次复制,在loop->tail->tailnode那儿加一个挡板
如果不是第一次复制,循环条件compare如果是exit_phi_map中的Key,就要进行一个更新
添加icmp, br_i1,label的指令
和内联一样,准备一个map保存原block与现在block的对应关系
进入复制,exit块和head块不复制,复制ir
如果v_new_valueMap中有,则要替换成最后使用值,而不能用原值(对于phi中有的值的处理方式)
又如果是变化过的中间变量 比如%6= add nsw i32 %2,1,复制第一次后变为%8 = add nsw i32 %6,1 做一个%6-----%8
更新两个map:
//如果在另两个表中的对应value里有v_dest,要更新 //如果v_new_valueMap有了新对应关系,比如本来记录了%2( %3) = phi i32[0 , %0], [%6 , %5] //然后other_new_valueMap中%6与它复制的下一条左值%8有了%6----%8对应,进行替换
基本块每处理完一轮接一次,phi每处理完一轮处理一次
一次复制循环跑完,在exit_phi_map更新一个出去时phi的值, 内容从v_new_valueMap中取
最后给exit_block加一些phi,其实就是把exit_phi_map的最新内容插回去
specialValueReplace修改一下后面用到的,改成新phi左值
多维数组初始化思路:
使用了递归,每读到一个InitValList就递归进下一层,每次传入参数有6个,当前语法树的节点,符号表中存储的这个数组的value,当前处理的gep起始层,当前起始层的base地址begin_offset_value,一个表示进位的carry数组,这个数组主要用于计算当前存储元素位置的每一维度的偏移值,一个cur_lpar表示进入的InitValList的嵌套数,主要是在这个InitValList处理完之后可能要对对应层数进行进位处理。
因为有递归,这个函数就只处理当前的InitValList层,然后与下一层对接。对当前层,局部变量有bool类型的come_num,因为如果是num之后的{},会影响下一层{}的起始偏移量,递归前要先进位。有record数组,用于记录一组gep的各个基地址变化,因为比如一个三维数组,不是每个变量值初始化都要三句gep,它可能与之前某个元素第一二层基地址相同,就可以直接从record数组取。
然后就是遇到InitValList就进递归,但是要处理好进递归前和递归完后可能需要的进位,遇到具体值就结合着begin_offset_value和record数组找基地址,注意需不需要进位,找准位置存储。
前提:
first_init:当前是不是第一次gep,如果是就从第一层开始gep,如果不是就直接看最后一层
record数组记录上一层的%value,比如要对第三层gep了,从第二层取出第二层得到的base地址
如果读到InitValList
分类:
if(init_val_list->left==NULL),//解决空InitValList的情况,即{},将起点记录进tmp_carry,用于地址处理
如果这层InitValList还没有走过Num,tmp_carry存一下,进递归,cur_lpar +1
这层已经走过num,如果上一个是num,还需要先进位,更新一下要进递归的start_layer
走完这个InitValList,如果前面没有过Num,通过cur_lpar更新一下进位。否则,根据Num算出需要怎么进
如果读到不是InitValList:
先判断下是不是first_init
是first_init,从start_layer层处理到最后一层地址,base地址是begin_offset_value和record数组值
不是first_init,直接处理最后一层
根据carry数组进行是否在上次的基础上需要进位的判断:
不需要进位,直接carry最后一位+1的offset存上就行
需要进位
进位,拿到进位后的Index,从变化的那一位开始gep,base地址从record取
短路思路 TODO 试试&&的右是&&:
用栈解决嵌套&& ||,|| 是br_i1先走false block,再走true block,
在if语句读到条件的根是短路时,就先把当前根压入栈
handle_and:如果左值也是logic_expr,先将它入栈,然后再递归调用handle_and或handle_or。否则,也先将左值入栈,然后根据这个条件生成ir返回一个ret,加一条br_i1到S_and。
如果右值也是logic_expr,也将它入栈,然后递归操作。否则,将右值也压入栈(在check步骤会出栈),然后看栈中上一级是&&还是||,决定生成的br_i1投入S_and还是S_or
handle_or:如果左右是&&,left:handle_and之后reduce_and,参数直接传入当前Index。right:是值,hanle_or走到处理后可以reduce_or(是||可以都br到这)
不管left还是right,遇到&&,走完后都可以reduce_and(||接&&才能这样,因为可以确定一定跳转到当前位置,但是&&接&&就不行,因为得跳到更远的地方,正如||接||,也会跳到更远的地方,&&接||也不行,错了也跳远了)
最后回到if的处理地,也要再reduce_and,reduce_or一次
bison与flex
yylex()是返回值的,不出错的情形下,它返回匹配模式的token,这就是它可以和bison生成代码一起协作的基础bison的yyparse()中:
if (yychar == YYEMPTY) { YYDPRINTF ((stderr, "Reading a token: ")); yychar = yylex (); /* 调用词法分析器解析一个token */ /* * 参看 3.1.3 小节,词法分析器工作流程 }ANTLR:LL* ,预测分析法
Bison:LALR,与lr(1)的区别是会将同心集进行合并,项目集数量会与LR(0)相同,比如会将3,6合在一起
LR文法功能更强,几乎能支持所有上下文无关文法。ANTLR有visitor模式
visitor模式:总结一下,访问者模式可以理解为:为操作某一对象的一组元素抽象出一组接口,配合对象元素的一个
accept()操作,从而实现了不需要修改对象元素而给该元素提供不一样操作的目的。
continue:
用S_continue栈
一进while循环就把目前的t_index值压入栈,在while走完把这个起始位置弹出
每读到一条while语句,就从栈中把栈top的while index作为跳转位置赋过去就行
break:
进入while,处理{} block,进入block之前while_scope++,处理完之后while_scope--
读到break stmt,创建一条br压入栈,false_location设为-while_scope
在while语句结束时,进行reduce,参数传入当前while结束处于的t_index
reduce_break中,如果while_scope匹配合适,则将当前br的true location赋为传入的t_index参数
return:
若有多返回语句,使用只有一句return的方法
S_return栈
多返回语句,将br压入栈
在func_def中,最后处理ret时,用当前index,处理栈中的所有跳转位置赋值
cal_expr:
后序遍历语法树,拿到后缀表达式
如果是!开头的,返回real值,表明需不需要非。如果是- !,就老实xor
gepFuse:
读到gep,如果偏移一直是常数,可以算出总偏移,然后存在ival,如果不是常数,标记到此为止已经不能完全算出,对能算出的ir做个标记,如果在不能完全算出之后,后面又出现了几条偏移常数的gep连在一起,还是照样算偏移,也要做另一种标记,并记录下gep合并偏移后的base基地址
第二次遍历ir, 删除ir
如果一条gep有可删标记,并且def_use链上的use的user都能算出偏移且仍是gep指令,就可删。然后分两种情况gep改成第一条gep的基地址或者前面有不能化简的了,就用记下的base基地址
寄存器分配:
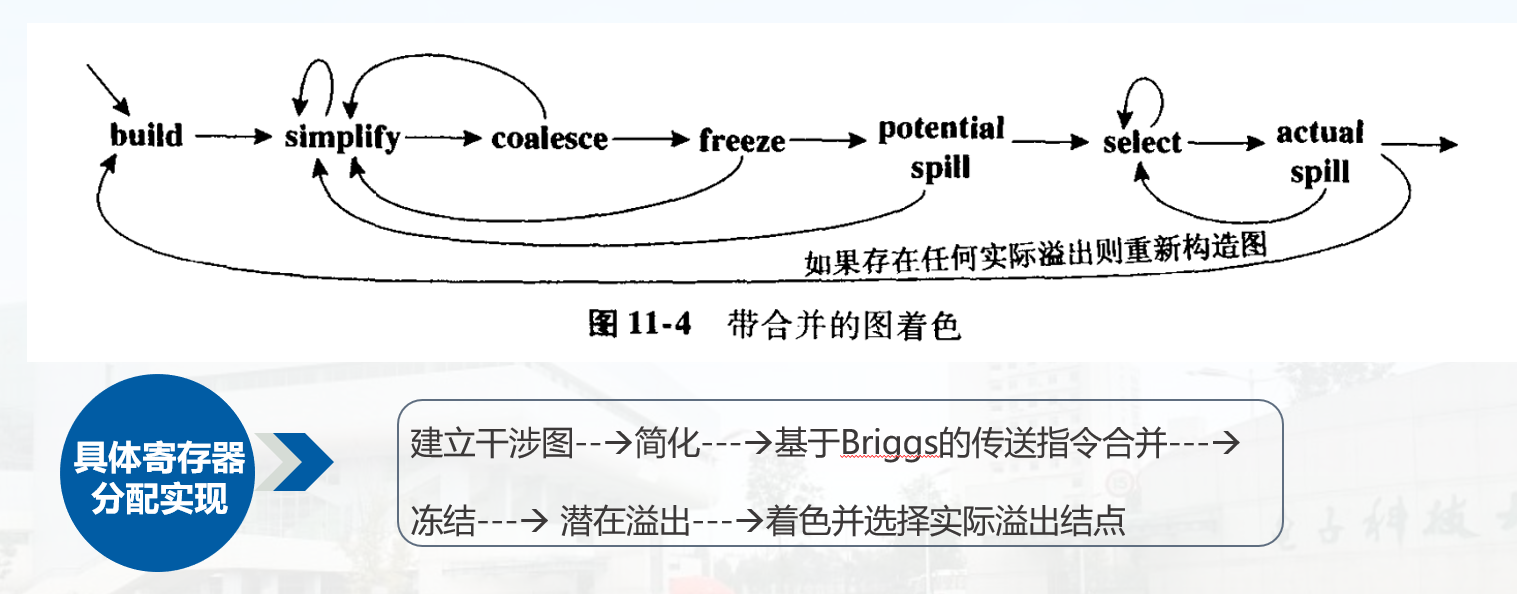
简化:删除 低度数、传送无关 的结点
冻结:寻找一个度数低的传送有关结点冻结
建立干涉图时,如果copyOperation的lhs 是最后一次出现(range是end),把这个传送指令加入workListMoves。
//为什么要live <---live\use(I) //mov dst,src不应是直接冲突关系,而是潜在可合并关系
makeWorkList:
spillWorklist:加入高度数节点表 degree >= K
freezeWorklist:低度数的有传送指令的
剩下的都进simplifyWorklist
走流程:
simplify:将拿出的Node入selectStack,邻结点度数要减,如果刚好到K-1的话:
activesMoves我们好像没遇见过 如果该节点有传送指令,可以加到workListMoves中准备合并
将结点从spillWorkList拿出来,加入简化的或冻结的
coalesce:如果满足保守合并要求
combine:move u , v
v->alias = u,将v加入coalescedNodes,修改一下邻节点度数等
getAlias:
while (HashSetFind(coalescedNodes, node)) node = node->alias;
freeze调用freezeMoves:
遍历与freeze node有传送节点的Node n,把n与freeze node的move从workListMoves中去除,并
如果n也是低度数传送无关节点了,放到simplifyWorkList里面
selectSpill:
//从高度数结点集(spillWorkSet)中启发式选取结点 x , 挪到低度数结点集(simplifyWorkSet)中 // 冻结 x 相关的move
着色:
具体图着色略,把有alias关系的Node(合并则共色) put入colorMap
如果有spillNodes
对溢出节点进行处理,再进行一次图着色
正则文法不能处理左递归,但上下文无关文法可以。LL文法和LR文法都是上下文无关文法的子集。LL文法不支持左递归,但是antlr也是基于LL文法的,并且它允许左递归(ANTLR在内部会自动识别并消除左递归,转换成等价的非左递归形式、ANTLR使用了一种扩展的LL(*)分析算法,可以处理某些形式的左递归)。
LL(1)文法的1:LL(1)文法仅依赖于当前输入符号来确定下一步的产生式,使用1个符号的预测集。LR(0):从左向右对串进行扫描;R: 最右推导;0: 不检查输入串,直接预测(只要进入归约状态,就进行归约);LR(1) : 为了解决SLR(1)中的问题,我们用向前搜索符代替follow集合的做法。
first集与follow集:First(X)表示非终结符X可能开始的所有终结符的集合;Follow(A)表示可能出现在非终结符A之后的所有终结符的集合。
epuber
http协议是请求-响应的意思是服务端不能主动给客户端发消息,websocket双端通信,服务端完成一个convert task,就可以给客户端发消息,实现了异步通信,解决了阻塞
WebSocketConfig
这个文件的作用是配置WebSocket支持,并将自定义的WebSocket处理程序注册到应用程序中,使用WebSocketHandlerRegistry来注册一个名为"/ws/session"的WebSocket处理程序,并设置允许所有来源的跨域请求
ExecutorConfig
我们使用Executors.newFixedThreadPool方法创建一个固定大小的线程池,大小为8个线程。这个线程池可以用于执行应用程序中的异步任务或并发操作。
Message
@Data @NoArgsConstructor @AllArgsConstructor public class Message { private String type; private String value; }UploadController
遍历每个上传的文件:
Service.convert(new MappingTask(fileService.multipartFileToFile(file), fileService.multipartFileToFile(f), impl, sessionId, fileId), () -> sessionService.notify_message(sessionId,fileId)); ConvertTask implement Runnable,run方法实现convert
serviceImpl
@Override public void submit(MappingTask task, WebSocketClientSyncCallback webSocketClientSyncCallback) throws IOException, InterruptedException { var future=executorService.submit(task); //加入task if(sessionService.find(task.getSessionId())!=null) sessionService.find(task.getSessionId()).addTask(future); new Thread(()->{ while (!future.isDone()) { try { TimeUnit.MILLISECONDS.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } } try { webSocketClientSyncCallback.callback(); } catch (IOException e) { throw new RuntimeException(e); } }).start(); }其中
public interface WebSocketClientSyncCallback { void callback() throws IOException; }() -> sessionService.notify_message(sessionId,fileId)是一个Lambda表达式,它实现了WebSocketClientSyncCallback接口中的callback方法。
由于WebSocketClientSyncCallback接口只有一个callback方法,因此可以使用Lambda表达式来实现该接口。在controller层中,() -> sessionService.notify_message(sessionId,fileId)实际上是WebSocketClientSyncCallback接口的一个实例
SessionService
管理Session的,不同的session有不同的session.id
private val sessions = ConcurrentHashMap<String, SessionContext>(); fun new(session: WebSocketSession) { sessions[session.id] = SessionContext(session) }找到对应的session,再单独调find、notify等
SessionContext
private WebSocketSession session; private List<Future<?>> tasks=new ArrayList<>();SessionHandler:
afterConnectionEstablished:
建立新session
sendMessage:session.sendMessage(new TextMessage(objectMapper.writeValueAsBytes(new Message("sessionId",session.getId()))));
afterConnectionClosed:destroy session
数据库复习
编译前端
analyse得Query
planner_->do_planner(query, context);,生成DDL语句和DML语句的查询执行计划
将查询执行计划转换成对应的算子树,DML语句convert_plan_executor将查询计划转为执行器(update,insert......)
遍历算子树并执行算子生成执行结果
查询计划(Query Plan)是指数据库系统在执行查询时生成的一个执行计划,它描述了数据库系统如何执行查询,包括使用哪些索引、如何连接表、如何过滤数据等等。
算子树(Operator Tree)是查询计划的一种表示方式,它是一个树形结构,每个节点表示一个算子(Operator),如扫描表、过滤数据、连接表等等。
